078
15.11.2025, 18:25 Uhr
Ordoban
|
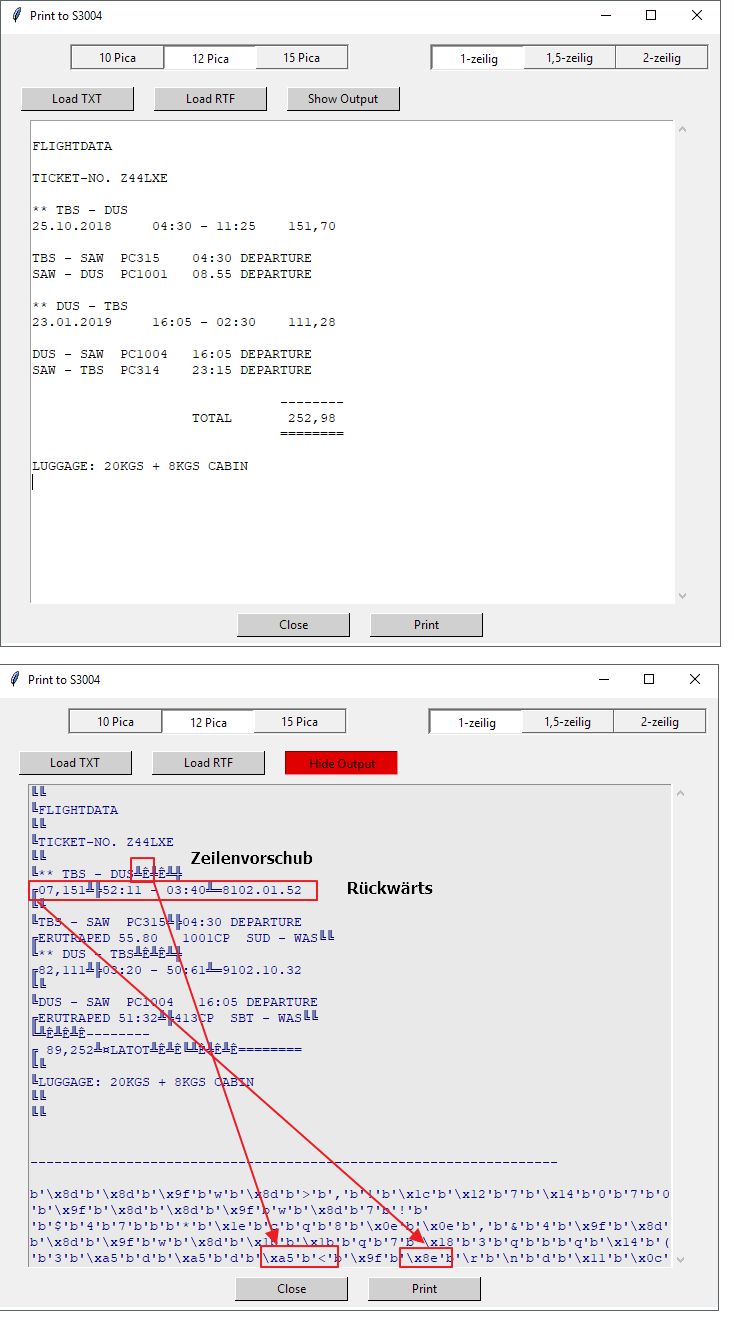
Aha. Diese Tabellen sind nur 128 Werte. Damit ist klar, warum die Richtung ascii2ddr für Umlaute nicht funktioniert. Die Umlaute sind da schlicht nicht drin. Du könntest die Tabelle um die Umlaute erweitern. Wie, ist abhängig von der Codepage:
CP1250 (Windows bis ca. win7)
ÄÖÜäöüß ---> c4 d6 dc e4 f6 fc df
IBM850 (DOS)
ÄÖÜäöüß ---> 8e 99 9a 84 94 81 e1
UTF8 (Windows ab ca. 8, Linux, MacOS etc.)
ÄÖÜäöüß ---> c384 c396 c39c c3a4 c3b6 c3bc c39f
(jaaaa, bei UTF8 sind Umlaute 2 Bytes...)
Für CP1250 würde das etwa so aussehen:
| Quellcode: |
char ascii2ddr [256] = {
0x71,0x71,0x71,0x71,0x71,0x71,0x71,0x71,0x71,0x91,0x77,0x71,0x71,0x92,
0x71,0x71,0x71,0x71,0x71,0x71,0x71,0x71,0x71,0x71,0x71,0x71,0x71,0x71,
0x71,71,0x71,0x71,0x71,0x42,0x43,0x41,0x48,0x04,0x02,0x17,0x1D,0x1F,0x1B,0x25,
0x64,0x62,0x63,0x40,0x0D,0x11,0x10,0x0F,0x0E,0x0C,0x0B,0x0A,0x09,0x08,0x13,
0x3B,0x71,0x2E,0x71,0x35,0x71,0x30,0x18,0x20,0x14,0x34,0x3E,0x1C,0x12,0x21,
0x32,0x24,0x2C,0x16,0x2A,0x1E,0x2F,0x1A,0x36,0x33,0x37,0x28,0x22,0x2D,0x26,
0x31,0x38,0x71,0x71,0x71,0x19,0x01,0x2B,0x61,0x4E,0x57,0x53,0x5A,0x49,0x60,
0x55,0x05,0x4B,0x50,0x4D,0x4A,0x5C,0x5E,0x5B,0x52,0x59,0x58,0x56,0x5D,0x4F,
0x4C,0x5F,0x51,0x54,0x71,0x27,0x71,0x71,0x71,
0x71, 0x71, 0x71, 0x71, 0x71, 0x71, 0x71, 0x71, 0x71, 0x71, 0x71, 0x71, 0x71, 0x71, 0x71, 0x71, // 8x
0x71, 0x71, 0x71, 0x71, 0x71, 0x71, 0x71, 0x71, 0x71, 0x71, 0x71, 0x71, 0x71, 0x71, 0x71, 0x71, // 9x
0x71, 0x71, 0x71, 0x71, 0x71, 0x71, 0x71, 0x3d, 0x71, 0x71, 0x71, 0x71, 0x71, 0x71, 0x71, 0x71, // ax
0x71, 0x71, 0x15, 0x23, 0x71, 0x71, 0x71, 0x71, 0x71, 0x71, 0x71, 0x71, 0x71, 0x71, 0x71, 0x71, // bx
0x71, 0x71, 0x71, 0x71, 0x3f, 0x71, 0x71, 0x71, 0x71, 0x71, 0x71, 0x71, 0x71, 0x71, 0x71, 0x71, // cx
0x71, 0x71, 0x71, 0x71, 0x71, 0x71, 0x3c, 0x71, 0x71, 0x71, 0x71, 0x71, 0x3a, 0x71, 0x71, 0x47, // dx
0x71, 0x71, 0x71, 0x71, 0x65, 0x71, 0x71, 0x71, 0x71, 0x71, 0x71, 0x71, 0x71, 0x71, 0x71, 0x71, // ex
0x71, 0x71, 0x71, 0x71, 0x71, 0x71, 0x66, 0x71, 0x71, 0x71, 0x71, 0x71, 0x67, 0x71, 0x71, 0x71} // fx
|
Es muss irgendwo im Programm eine Begrenzung auf 128 Charpositionen stehen. Die müsstest du dann auf 256 erweitern. (oder ganz entfernen)
Bei der anderen Richtung wird das echt komisch. Da fehlen tatsächlich die Nummern. Die müssten etwa so sein:
| Quellcode: |
char ddr2ascii [128] = {
' ',' ',' ',' ',' ',' ',' ',' ','9','8','7','6','5','0','4','3', // 00-0F
'2','1','H',':','D','²','M','"','B','^','Q','*','G','(','O',')', // 10-1F
'C','I','V','³','K','+','X','|','U',' ','N','`','L','W','=','P', // 20-2F
'A','Y','J','S','E','?','R','T','Z','°','Ü',';','Ö','§','F','Ä', // 30-3F
'/','#','!','"','é','ç','è','ß','$','f','m','j','w','l','b','v', // 40-4F
'k','y','q','d','z','h','t','c','s','r','e','p','n','u','o','x', // 50-5F
'g','a','-','.',',','ä','ö','ü',' ',' ',' ',' ',' ',' ',' ',' ', // 60-6F
' ',' ',' ',' ',' ',' ',' ','\n',' ',' ',' ',' ',' ',' ',' ',' ' // 70-7F
};
|
Ich wundere mich echt, warum der bei dir trotzdem Nummern ausspuckt.
Und ich sehe hier noch ein anderes Problem. Woher weiß der Compiler, welche Codepage bzw. Codierung der verwenden soll? Wenn man sicherstellen will, dass da am Ende das richtige raus kommt, sollte man für Sonderzeichen die Hex-Codes der gewünschten Codepage verwenden. Etwa so (für CP1250):
| Quellcode: |
'A','Y','J','S','E','?','R','T','Z','°',0xDC,';',0xD6,'§','F',0xC4, // 30-3F
'/','#','!','"','é','ç','è',0xDF,'$','f','m','j','w','l','b','v', // 40-4F
'k','y','q','d','z','h','t','c','s','r','e','p','n','u','o','x', // 50-5F
'g','a','-','.',',',0xE4,0xF6,0xFC,' ',' ',' ',' ',' ',' ',' ',' ', // 60-6F
|
Edit: Zeile 8x vergessen...
Edit2: Ich sehe gerade als Datentyp "char". Bei Zahlen größer 127 sollte man "unsigned char" nehmen. Sonst kann es passieren, dass einem der Compiler Unsinn mit dem Vorzeichen macht - was genau solche blöden Fehler woe mit den Umlauten gibt.
--
Gruß
Stefan
Dieser Beitrag wurde am 15.11.2025 um 18:49 Uhr von Ordoban editiert. |